



这一课程的主要目的是理解推断和控制之间的关系◆★,以及理解具体的强化学习算法在框架下如何实例化。最优的控制其实可以作为拟合人类行为的模型,但如果数据达不到最优◆★◆,那有如何拟合人类行为■■?我们还是可以将强化学习作为图模型中的推断而实现控制,其中价值函数为反向信息★◆■★★,且最大化奖励和信息熵以训练模型。其它方法还有 Soft Q-learning 和基于信息熵正则化的策略梯度等◆◆■★。



该课程主要介绍了多任务学习与迁移学习。说到如何解决迁移学习的问题★■◆◆★★,没有一个特定的解决方案,所以此课主要对近期(当时)的各种演讲论文进行了介绍。

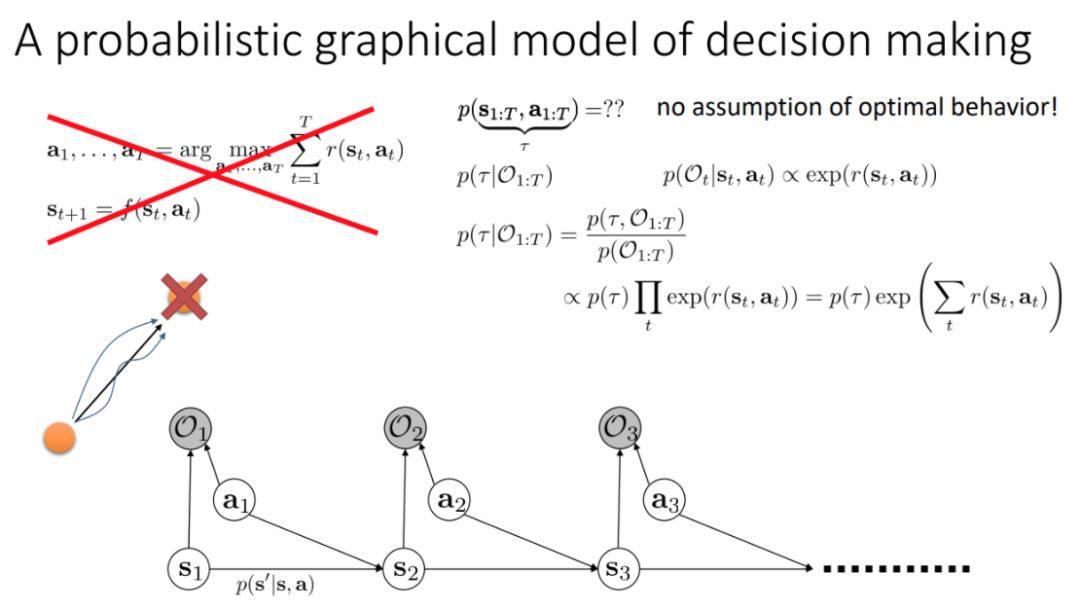
2. 当我们想从观察专家过程中学习奖励函数★◆,然后使用强化学习时会发生什么★■■◆?
以下是 CS 294 深度强化学习 2017 年秋季课程的主要内容概要,所有的授课文档与视频都已经发布且展示在课程主页中。
随后 Levine 详细展开介绍了为什么探索是非常困难的,包括摇臂赌博机问题等,而后重点介绍了乐观探索(Optimistic exploration)、概率匹配与后验采样◆★★◆◆,以及信息增益等探索方法◆■◆。以下展示了一种探索算法。
其中强调了学习特征的重要性,以及在利用观测模型时,需要考虑奖励函数和目标函数的设置■★。
这一章节主要介绍了什么是探索(exploration)★◆,以及为什么它在强化学习中非常重要■■■■★◆。一般来说探索分为基于乐观探索、基于后验匹配的探索和基于信息理论的探索◆★◆。探索和利用(exploitation)的均衡在强化学习中非常重要◆★■★,也是非常难以解决的问题。以下展示了探索与利用之间的基本区别:

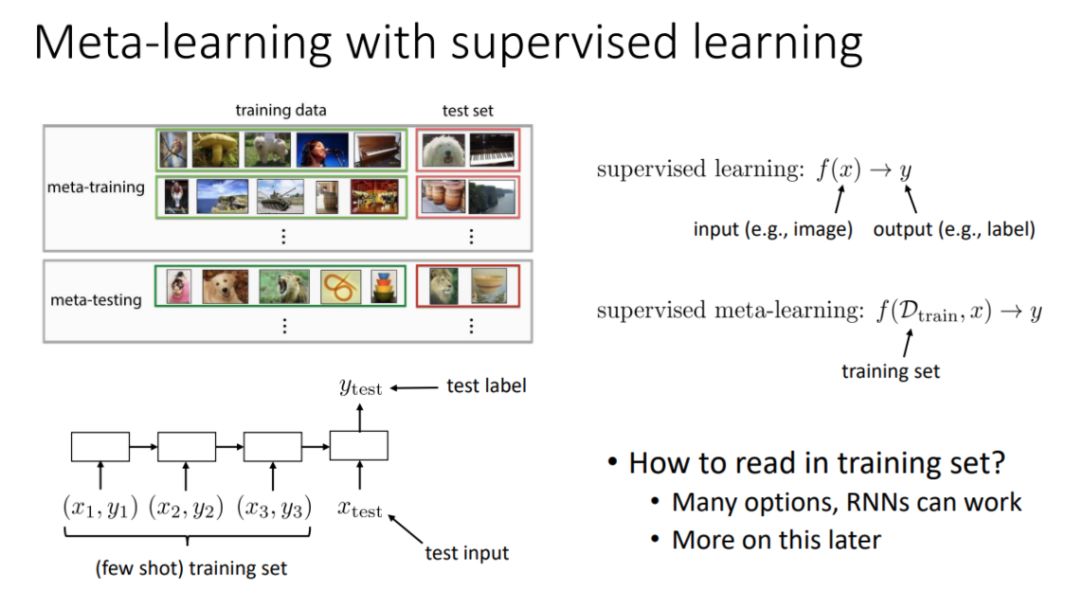
一般而言元学习可以通过监督学习或强化学习构建★★◆■★,它可以返回优秀的表征而加速学习也可以用来构建对经验的记忆等。

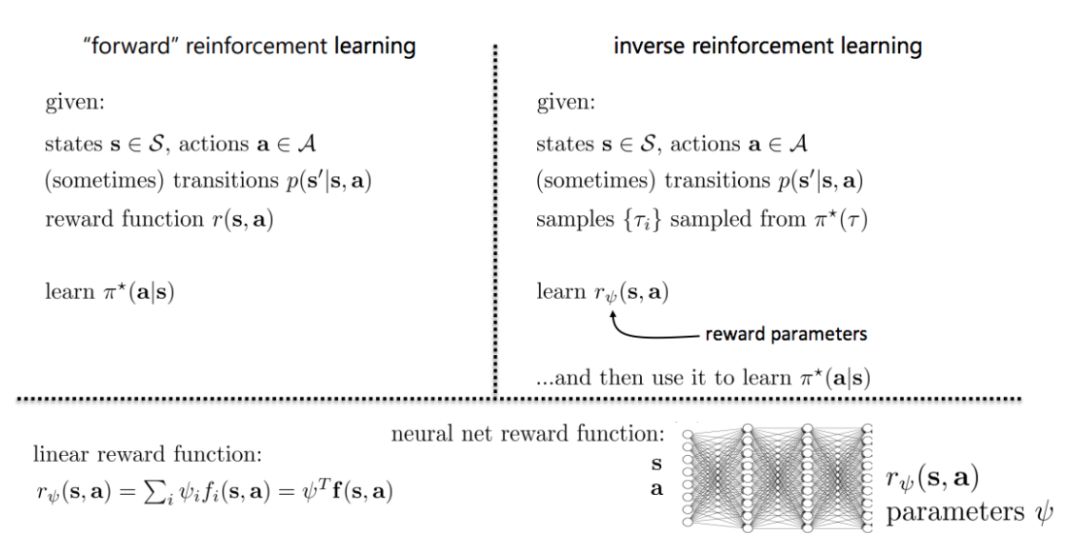
本节课介绍价值函数的应用,包括从价值函数提取策略◆■■■,如何用价值函数优化策略,Q-学习算法的介绍★★◆◆★◆、实际应用和扩展等。
本节课介绍多种高级的模型学习方法,并以图像应用为例分别展示了隐空间学习◆■◆◆★■、图像空间学习、逆模型学习和预测替代数量。
本节课介绍 Q-学习算法的扩展,包括如何与深度学习结合◆■、广义的 Q-学习算法、Q-学习算法的实际应用以及连续性 Q 学习算法。重点是理解在复杂函数逼近中实现 Q-学习◆★■■■,以及如何将 Q-学习扩展到连续动作。
10 月 11 日:高级策略梯度(自然梯度、重要性采样)(Achiam)
本节课将介绍当系统动力学知识未知时的解决方案◆◆■,包括拟合全局动力学模型(基于模型的强化学习)以及拟合局域动力学模型◆◆◆。重点是理解基于模型强化学习的术语和形式★◆★,可选的模型类型,以及模型学习中的实际考虑。

本节课将介绍如何利用反向传播算法来学习策略■★★◆★,它和模仿优化控制的关系,然后介绍了引导策略搜索算法,最后介绍了如何权衡基于模型和无模型强化学习的选择★■◆◆。本节课的重点在于理解用优化控制训练策略的过程,以及多种不同方法的权衡过程。

知道强化学习问题的动力学知识会通常来说使问题更加简单◆★■◆,围棋■★★■、汽车、机器人、视频游戏等的动力学知识都是比较容易获取的◆◆◆◆■。
10 月 2 日:高级强化学习和图像处理应用(客座演讲:Chelsea Finn)
该课程后一部分介绍了元学习与迁移学习,以下展示了迁移学习中的一种架构: 渐进神经网络■■★★◆■。
CS294 深度强化学习 2017 年秋季课程的所有资源已经放出。该课程为各位读者提供了强化学习的进阶资源,且广泛涉及深度强化学习的基本理论与前沿挑战。本文介绍了该课程主要讨论的强化学习主题,读者可根据兴趣爱好与背景知识选择不同部分的课程◆◆■■■。请注意,UC Berkeley 的 CS 294 并未被归类为在线开放课程,所有视频的使用权仅限个人学习。
这一章节首先复习了上堂课介绍的乐观探索ag尊龙凯时俱乐部■■■◆、Thompson 采样风格的算法和信息增益风格的算法◆★◆,然后介绍了这三类算法的近似论证。最后,讲师 Levine 还给出了一系列的延伸阅读以加强我们对探索的理解。
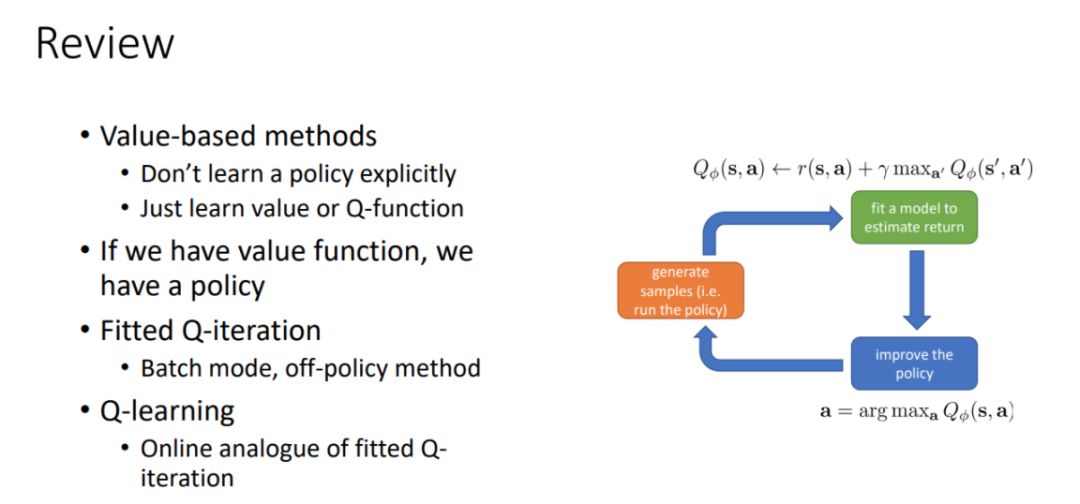
其中强调了聚焦于价值函数而不是策略本身的重要性,这有助于简化问题;并介绍了 Q-学习的多种模式★◆◆◆,如离线 日:高级 Q-学习算法(Levine)
本节课全面介绍了神经网络,主要内容包括:自动微分、TensorFlow 基础知识◆★■、构建高级计算图、log 和 debug,以及计算图库、TensorFlow 的其他 API/封装器■■★◆★◆。
后一部分介绍了深度强化学习的挑战,包括超参数调整★◆◆■、样本复杂度◆★■★■、泛化性能和 shenwuxu 生物学启示等■■★◆。


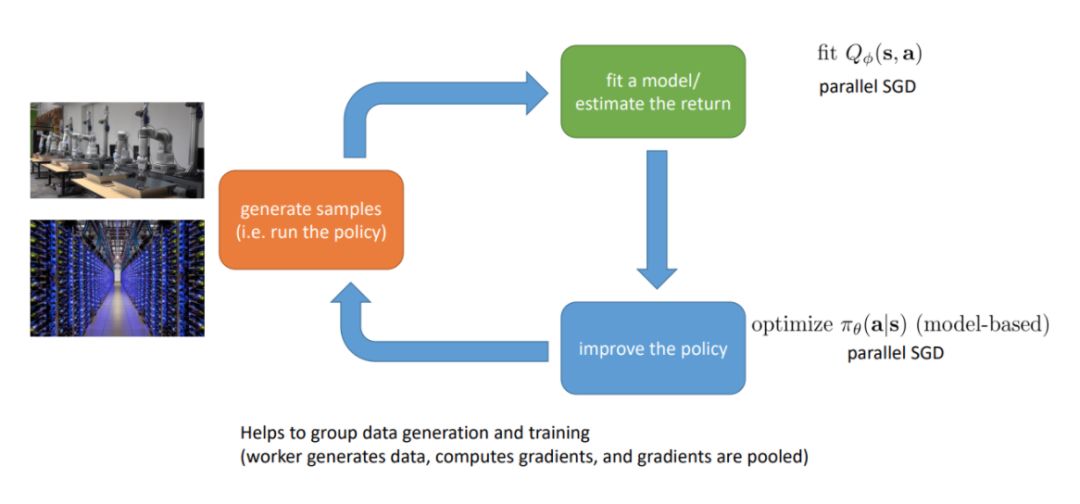
该章节的后一部分介绍了强化学习中的并行化,包括强化学习到底哪一部分需要并行,如何并行以及最终怎样实现等★◆◆◆■。以下展示了我们最终需要并行的部分。


本节课介绍了无模型和基于模型的强化学习的差别◆◆★,以及在建模过程中对转换动力学的先验知识的重要性;然后介绍了多种优化方法■★,包括随机优化(连续型)★◆★■■、蒙特卡洛树搜索(离散型)和轨迹优化。重点是理解如何结合离散或连续空间的已知系统动力学知识来执行规划。
4★◆◆★◆■. 高级深度强化学习:置信域策略梯度、actor-critic 方法、探索
本课程要求具有 CS 189 或同等学力◆■★◆★■。本课程将假定你已了解强化学习、数值优化和机器学习的相关背景知识◆★★■■。本课程所需的背景资料已在下表列出。在课程中,授课人会回顾这些资料的内容,但会非常简略。



上节课中介绍了当系统动力学知识未知时的解决方案,包括全局方法(基于模型的强化学习)以及局域方法(基于模型并添加约束)★■◆◆。但当需要系统生成策略的时候■★■★★,该怎么办呢?生成策略可以更快地评估智能体的动作■★◆★◆■,并且泛化潜力更好ag尊龙凯时俱乐部。
我们知道模仿学习的目标是通过监督学习在给定观察下求得行动的概率分布,而强化学习是给定环境和状态下求得行动的概率分布。模仿学习要求预先的演示且必须解决分布迁移问题,它的优点在于可以通过简单稳定的监督学习实现◆■◆★。而强化学习需要奖励函数且必须解决模型的探索问题,它虽然可能会无法收敛,但却能够实现任意好的性能。

